什么是502错误?
当用户访问网站时遇到「502 Bad Gateway」错误,通常意味着服务器之间的通信出现了问题,作为网关或代理的服务器(如Nginx、apache)未能从上游服务器(如应用服务器、数据库)获得有效响应,这种错误并非由用户端设备或网络引起,而是服务器配置、资源限制或程序异常导致的临时中断。

为什么需要关注日志?
502错误可能由多种原因触发,且表现形式相似,仅通过页面提示无法精准定位问题根源,必须结合服务器日志分析,日志记录了请求处理过程中的详细信息,包括错误类型、时间戳、触发模块及具体报错描述,忽略日志排查,可能导致问题反复出现,甚至引发更严重的服务中断。
**一、502错误的常见原因
1、上游服务器无响应
网关服务器(如Nginx)配置了反向代理,将请求转发至后端应用服务器(如Tomcat、Node.js),若应用服务器崩溃、端口未开放或防火墙拦截,网关无法获取响应,返回502错误。
典型日志特征:connect() failed (111: Connection refused) 或upstream timed out。
2、反向代理配置错误

代理服务器的超时时间设置过短、缓冲区不足,或负载均衡策略不合理,可能导致上游服务器未及时返回数据,PHP-FPM进程池耗尽时,Nginx因等待超时触发502。
日志线索:upstream sent too big header 或upstream prematurely closed connection。
3、资源超限
服务器CPU、内存、磁盘I/O等资源耗尽,导致应用进程崩溃,常见于高并发场景或程序存在内存泄漏。
日志表现:Cannot allocate memory 或worker_connections are not enough。
4、第三方服务故障
若网站依赖外部API、CDN或数据库服务,这些组件的异常可能间接引发502错误,数据库连接池耗尽导致请求堆积。
**二、如何通过日志定位问题?
**步骤1:确定错误发生时间
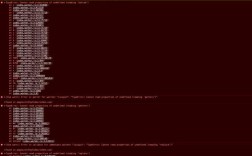
查看访问日志(如Nginx的access.log),筛选出返回502状态码的请求记录,记录时间戳和对应的客户端IP,示例命令:
- grep "502" /var/log/nginx/access.log | awk '{print $4}' | uniq -c
**步骤2:分析错误日志详情
打开错误日志(如Nginx的error.log),根据时间戳定位具体报错条目,重点关注以下关键词:
Connection refused:上游服务器未运行或端口不通。
upstream timed out:代理超时时间设置过短。
No buffer space available:系统资源不足。
**步骤3:验证上游服务器状态
通过命令行工具直接测试上游服务是否可用:
- curl -I http://localhost:8080 # 替换为实际应用端口
若返回Connection refused,需检查应用进程是否运行、端口监听情况及防火墙规则。
**步骤4:检查资源使用情况
使用系统监控工具(如top、htop、vmstat)查看服务器负载:
内存不足:free -h显示可用内存接近0,或OOM Killer进程被触发。
CPU满载:%wa(I/O等待)数值过高可能意味着磁盘瓶颈。
进程数超限:ps aux | wc -l统计进程数量,对比系统最大限制(ulimit -u)。
**三、针对性解决方案
**场景1:上游服务崩溃
临时处理:重启应用服务(如systemctl restart nginx)。
长期优化:
- 部署进程监控工具(如Supervisor),实现崩溃自动重启。
- 启用健康检查机制,负载均衡器自动屏蔽异常节点。
**场景2:代理配置不合理
- 调整Nginx超时参数:
- location / {
- proxy_connect_timeout 60s;
- proxy_read_timeout 120s;
- proxy_send_timeout 120s;
- proxy_buffer_size 16k;
- proxy_buffers 8 32k;
- }
- 若使用PHP-FPM,增加进程池数量并限制单个进程内存:
- pm = dynamic
- pm.max_children = 50
- pm.start_servers = 10
- pm.max_spare_servers = 30
**场景3:服务器资源不足
- 扩容硬件配置或优化程序性能。
- 限制并发连接数,防止突发流量击穿服务。
- 使用缓存(如Redis)减少数据库查询压力。
**场景4:第三方服务异常
- 为关键API调用添加重试机制和熔断策略。
- 配置备用服务节点,主节点故障时自动切换。
个人观点
502错误本质是系统架构中某一环节的“断裂”,作为运维人员,需建立完整的监控体系(如Prometheus+AlertManager),实时追踪服务状态,定期进行压力测试,评估系统的容灾能力,对于开发者而言,代码中需加入异常捕获和资源释放逻辑,避免单点故障扩散,快速响应与主动预防的结合,才是降低502错误发生率的核心。