在处理数据时,去重是一个常见的需求,表格去重主要是为了删除重复的行或列,确保数据的完整性和准确性,以下是关于如何进行表格去重的详细步骤和注意事项:
理解重复数据的概念
在开始去重之前,首先需要明确什么是重复数据,重复数据指的是在同一张表格中具有完全相同的值的行或列,根据实际需求,重复的定义可能会有所不同,在某些情况下,只有特定的几列需要被考虑是否重复。

选择合适的工具
电子表格软件:如Microsoft Excel、Google Sheets等,这些工具提供了直观的用户界面和强大的数据处理功能。
数据库管理系统:如MySQL、PostgreSQL等,适用于处理大量数据的情况。
编程语言:如Python、R等,通过编写脚本可以实现更复杂的去重逻辑。
使用电子表格软件去重
以Microsoft Excel为例,以下是基本的去重步骤:
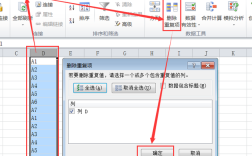
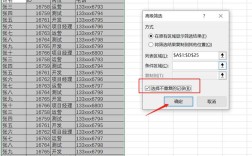
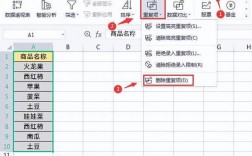
打开Excel文件并选择包含重复数据的表格区域。
点击“数据”选项卡下的“删除重复项”按钮。

在弹出的对话框中,选择要检查重复值的列。
点击“确定”,Excel将自动删除选中列中重复的行。
使用数据库管理系统去重
对于存储在数据库中的表格数据,可以使用SQL语句进行去重,以下是一个示例:
DELETE FROM your_table
WHERE id NOT IN (
SELECT MIN(id)
FROM your_table
GROUP BY column1, column2, ...
);这条SQL语句的作用是保留每个组(由column1, column2, ...定义)中id最小的那一行,删除其他重复的行。
使用编程语言去重
以Python为例,可以使用pandas库来处理表格数据,以下是一个简单的例子:
import pandas as pd
读取CSV文件到DataFrame
df = pd.read_csv('your_file.csv')
去重,保留第一次出现的重复项
df_unique = df.drop_duplicates()
保存结果到新的CSV文件
df_unique.to_csv('unique_file.csv', index=False)注意事项
备份数据:在进行任何数据操作之前,都应该备份原始数据以防万一。

理解业务规则:去重前要清楚哪些数据应该被视为重复,这可能需要与业务部门沟通确认。
测试:在正式环境中应用去重操作前,应该在小规模的数据样本上进行测试,确保逻辑正确无误。
相关问答FAQs
Q1: 如果我只想去除特定列的重复项怎么办?
A1: 无论是使用电子表格软件、数据库还是编程语言,大多数工具都允许你指定哪些列用于判断重复,在Excel中,你可以在“删除重复项”对话框中选择特定的列;在SQL中,可以在GROUP BY子句中指定列名;在Python的pandas库中,可以使用subset参数来指定列。
Q2: 去重后如何恢复被误删的数据?
A2: 如果已经对数据进行了去重并且没有备份原始数据,那么恢复被误删的数据可能会比较困难,一种可能的方法是检查是否有日志记录或者事务历史可以回滚到某个点,另一种方法是尝试从其他来源重建丢失的数据,比如联系数据提供者请求原始数据集或者使用数据恢复服务,预防措施如定期备份是非常重要的。