提取网页中的图片可以通过多种方法实现,包括使用浏览器插件、在线工具和编写爬虫程序等,以下是几种常见的方法及其具体操作步骤:
一、使用浏览器插件
1、Fatkun图片批量下载

安装插件:在Chrome或Edge浏览器中,访问Chrome Web Store或Edge商店,搜索“Fatkun图片批量下载”,点击获取并安装插件。
使用方法:打开目标网页,确保页面加载完成,点击浏览器右上角的插件图标,选择“提取本页图片”,插件会自动扫描网页上的所有图片,并提供筛选功能,如按格式、大小、类别等进行筛选,选择需要的图片并点击下载按钮即可。
2、AIX智能下载器
安装插件:同样在Chrome或Edge浏览器中,访问Chrome Web Store或Edge商店,搜索“AIX智能下载器”,点击获取并安装插件。
使用方法:打开目标网页,确保页面加载完成,点击浏览器右上角的插件图标,选择“提取当前页面图片”,插件会自动扫描并显示所有可下载的图片,用户可以选择需要的图片进行下载。
3、ImageAssistant(图片助手)

安装插件:在Chrome浏览器中,访问Chrome Web Store,搜索“ImageAssistant”,点击获取并安装插件。
使用方法:打开目标网页,确保页面加载完成,点击浏览器右上角的插件图标,选择“提取本页图片”,插件会将页面上的所有图片以缩略图的形式展示出来,用户可以对缩略图添加筛选条件,然后选择需要的图片进行下载。
二、使用在线工具
1、Image Extractor
访问网站:打开浏览器,访问Image Extractor网站。
输入网址:在对话框中输入想要提取图片的网页地址,点击“Extract”按钮。
选择图片:网站会自动扫描并列出该网页上的所有图片,用户可以预览图片、查看图片大小和格式,并进行筛选。

下载图片:勾选需要下载的图片,点击“Download selected”按钮,将选中的图片打包为ZIP文件下载到本地。
三、使用Python编写爬虫程序
1、环境准备
确保已安装Python环境。
安装必要的库:pip install requests beautifulsoup4。
2、发送HTTP请求
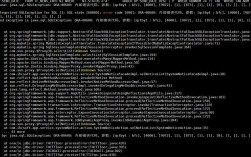
import requests
url = 'https://example.com'
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
print(f'Failed to retrieve content: {response.status_code}')3、解析网页内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
img_tags = soup.find_all('img')4、提取图片URL
import os
from urllib.parse import urljoin
image_urls = []
for img in img_tags:
img_url = img.get('src')
img_url = urljoin(url, img_url)
image_urls.append(img_url)5、下载并保存图片
save_folder = 'downloaded_images'
os.makedirs(save_folder, exist_ok=True)
for img_url in image_urls:
try:
img_response = requests.get(img_url, stream=True)
if img_response.status_code == 200:
img_name = os.path.basename(img_url)
img_path = os.path.join(save_folder, img_name)
with open(img_path, 'wb') as f:
for chunk in img_response.iter_content(1024):
f.write(chunk)
print(f'Downloaded: {img_url}')
else:
print(f'Failed to download {img_url}: {img_response.status_code}')
except Exception as e:
print(f'Error downloading {img_url}: {e}')四、使用浏览器内置功能
1、Chrome浏览器
右键点击图片,选择“另存为…”,将图片保存到指定位置。
如果需要批量下载,可以使用Chrome的开发者工具(F12),在Network标签下刷新页面,找到图片资源并复制链接进行下载。
2、Firefox浏览器
右键点击图片,选择“查看页面信息”,点击“媒体”,全选并另存为。
提取网页中的图片有多种方法可供选择,用户可以根据自己的需求和技术能力选择最合适的方法,无论是使用浏览器插件、在线工具还是编写爬虫程序,都可以高效地提取网页中的图片。