Nginx服务异常中断?可能是信号机制在"作祟"
作为网站运维的核心组件,Nginx的稳定性直接关系到用户体验,当服务器突然停止响应或日志中出现"signal"相关报错时,运维人员往往会一头雾水,本文将深入解析Nginx信号机制的原理,帮助您快速定位并解决由信号触发的服务异常。

一、Nginx信号机制的本质
Nginx采用多进程架构,主进程(Master Process)负责管理子进程(Worker Process),这种设计依赖操作系统提供的信号(Signal)机制实现进程间通信,当需要执行重启、关闭或配置重载时,系统通过发送特定信号指令触发Nginx的响应动作。
执行nginx -s reload命令时,实际是向主进程发送了SIGHUP信号,触发配置热更新,若信号传递过程出现异常,可能导致服务状态与预期不符,进而引发错误。
二、高频触发报错的信号类型
1、SIGTERM(信号15)
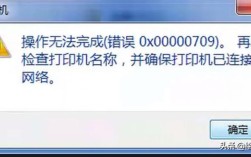
强制终止进程的默认信号,通常在执行nginx -s stop时触发,若主进程未正确关闭子进程,可能导致残留进程持续占用端口,后续重启时出现"Address already in use"错误。
2、SIGHUP(信号1)
配置重载信号,若新配置文件存在语法错误,主进程会拒绝加载并记录报错,但已运行的Worker进程不受影响,此时需排查nginx -t的检测结果。

3、SIGQUIT(信号3)
优雅关闭指令,等待当前请求处理完成后退出,若长时间未完成,可能因超时导致进程僵死,需结合日志中的请求处理时间分析。
4、SIGUSR1(信号10)
用于重新打开日志文件,若日志目录权限不足或磁盘空间耗尽,执行nginx -s reopen会触发报错,表现为日志停止更新。
三、实战:从报错日志定位信号问题
以下为典型信号报错日志及应对策略:
场景1:Master进程意外退出

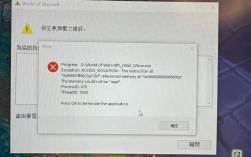
- [alert] 1234#0: worker process 5678 exited on signal 11 (SIGSEGV)
*分析*:Worker进程因段错误(Signal 11)崩溃,可能由第三方模块内存溢出或硬件故障导致,需通过gdb调试核心转储文件,或暂时禁用可疑模块验证。
场景2:热重载失败
- [error] 1234#0: invalid parameter "proxy_passs" in /etc/nginx/conf.d/app.conf:10
*应对*:配置语法错误会阻断SIGHUP信号生效,使用nginx -t -c /path/to/nginx.conf主动检测,修正拼写错误后再次重载。
场景3:端口占用冲突
- [emerg] 1234#0: bind() to 0.0.0.0:80 failed (98: Address already in use)
*排查*:旧进程未完全退出,执行lsof -i :80查找残留进程ID,通过kill -9 <PID>强制清理后重启服务。
四、规避信号问题的关键操作
1、规范进程管理
避免直接使用kill命令,优先通过nginx -s发送标准指令,若必须手动终止进程,建议向Master进程发送信号而非Worker进程。
2、配置预检机制
每次修改配置文件后,执行nginx -t进行语法校验,并观察测试环境的服务状态,确认无误后再同步至生产环境。
3、日志权限管理
确保Nginx运行用户对日志目录拥有写权限,定期清理过期日志文件,防止因磁盘空间不足导致SIGUSR1信号失效。
4、监控信号响应
通过ps aux | grep nginx观察进程树结构,确认Master进程与Worker进程的父子关系是否正常,异常情况下,Master进程ID应为1(容器环境除外)。
五、进阶:自定义信号处理逻辑
Nginx支持通过--with-debug编译选项启用高级调试功能,对于需要定制化信号处理的企业场景,可修改src/os/Unix/ngx_process.c源码,添加自定义信号处理函数,捕获SIGTERM信号时主动清理临时文件,避免资源泄露。
写在最后
信号机制是Nginx高效运维的基石,但也可能成为故障的导火索,建议在日常维护中建立"修改前备份、操作中监控、异常时回滚"的标准流程,根据个人经验,超过70%的信号相关报错源于配置失误或环境权限问题,系统性检查往往比盲目重启更有效。(作者:某运维团队技术负责人)