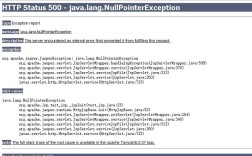
MongoDB报错问题分析与解决方案
在使用MongoDB进行数据存储和管理时,无论是新手开发者还是经验丰富的运维人员,都可能遇到各种报错信息,这些报错看似复杂,但通过系统化的分析和针对性处理,大多数问题都能快速解决,本文将从实际场景出发,梳理常见的MongoDB报错类型,并提供清晰的排查思路和解决方案,帮助用户高效应对数据库问题。

一、连接类报错:无法建立与数据库的通信
典型错误信息:
Failed to connect to [hostname]:27017
MongoNetworkError: Connection timed out
原因与排查:
1、网络配置问题:检查服务器防火墙是否开放27017端口,或云服务商的安全组规则是否允许访问。

2、MongoDB服务未启动:通过命令systemctl status mongod(Linux)或服务管理器(Windows)确认服务状态。
3、认证信息错误:若启用了身份验证,需检查连接字符串中的用户名、密码及认证数据库(如admin)是否正确。
解决方案:
- 临时关闭防火墙测试连接:sudo ufw disable(仅限测试环境)。
- 重启MongoDB服务:sudo systemctl restart mongod。
- 使用mongosh命令行工具验证凭据:

mongosh "mongodb://username:password@localhost:27017/dbname?authSource=admin"
二、操作冲突:主键重复与写锁竞争
典型错误信息:
E11000 duplicate key error collection
WriteConflictError: This operation conflicted with another operation
原因与排查:
1、唯一索引冲突:当插入或更新数据时,若字段被定义为唯一索引(如_id),重复值会触发此错误。
2、事务锁超限:高并发场景下,多个写操作可能因锁竞争导致超时。
解决方案:
唯一索引冲突:
- 检查插入数据是否包含已存在的_id或其他唯一字段值。
- 若业务允许重复,可考虑移除唯一索引,但需谨慎评估数据一致性。
写锁竞争:
- 优化事务粒度,减少单个操作耗时。
- 升级MongoDB版本以利用改进的并发控制机制(如WiredTiger引擎的文档级锁)。
三、查询性能问题:慢查询与索引缺失
典型错误信息:
- 无直接报错,但日志中出现COLLSCAN(全表扫描)警告。
- 客户端请求超时(如operation exceeded time limit)。
原因与排查:
1、未命中索引:查询条件未匹配现有索引,导致全表扫描。
2、索引设计不合理:复合索引字段顺序错误,或索引覆盖不足。
解决方案:
使用explain()分析查询计划:
db.collection.find({field: value}).explain("executionStats") 关注stage字段是否为IXSCAN(索引扫描),而非COLLSCAN。
创建或优化索引:
- 针对高频查询字段建立复合索引,注意字段顺序(精确匹配字段优先,范围查询字段置后)。
- 定期清理未使用的索引,避免写入性能下降。
四、存储引擎异常:磁盘空间不足与文件损坏
典型错误信息:
No space left on device
DBException: InvalidBSON: size is invalid
原因与排查:
1、磁盘空间耗尽:数据文件或日志文件占满存储空间。
2、数据文件损坏:服务器异常关机或硬件故障可能导致文件损坏。
解决方案:
扩容磁盘空间:
- 清理日志文件(mongod.log)或归档旧数据。
- 扩展云服务器磁盘容量,或迁移数据至新存储设备。
修复损坏数据:
- 使用mongod --repair命令尝试修复(需停止服务)。
- 从备份中恢复数据,强调定期备份的重要性。
五、预防性措施:降低报错发生概率
1、监控与告警:部署Prometheus+Grafana监控集群状态,关注CPU、内存、磁盘I/O等指标。
2、定期维护:执行compact命令回收存储碎片,或使用validate检查集合完整性。
3、权限最小化:为应用分配仅具备必要权限的数据库账号,避免误操作。
个人观点
MongoDB的报错信息本质上是系统与开发者的一种“对话”,与其被动应对错误,不如主动建立预防机制:通过合理的索引设计、资源监控和定期维护,多数问题可被扼杀在萌芽阶段,对于关键业务,务必落实备份策略,并定期演练数据恢复流程,技术团队的核心能力不仅体现在故障修复速度上,更在于能否通过架构优化降低故障发生率。