数据库并行执行中的SQL报错分析与解决方案
在高并发、大数据量场景下,数据库的并行处理能力是保障业务稳定的关键,当多个线程或进程同时执行SQL操作时,常会遇到意料之外的报错,这些错误轻则导致查询中断,重则引发数据不一致甚至系统崩溃,本文将深入探讨并行环境下SQL报错的常见类型、原因及高效排查方法,为开发者提供实用指南。

一、并行执行中的典型SQL报错场景
1、锁冲突(Lock Contention)
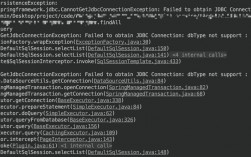
当多个事务尝试同时修改同一行数据时,可能触发锁等待超时(Lock Wait Timeout)或死锁(Deadlock),事务A持有某行数据的排他锁(X锁),事务B尝试获取该锁时会被阻塞,若超时仍未释放,则会抛出错误。
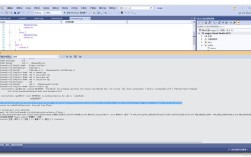
常见报错信息:Lock wait timeout exceeded; try restarting transaction
解决方案:优化事务粒度,缩短事务执行时间;调整锁超时参数(如innodb_lock_wait_timeout);使用乐观锁机制替代悲观锁。
2、资源竞争引发异常

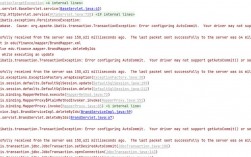
并行操作可能耗尽数据库连接池、内存或临时表空间,大量并发查询同时占用临时表空间时,可能触发The table '/tmp/#sql_xxx' is full错误。
解决方案:监控资源使用率,动态扩容;优化SQL语句,减少临时表生成(如避免ORDER BY、GROUP BY中的大表操作)。
3、死锁(Deadlock)
两个及以上事务相互等待对方释放锁时,数据库会自动检测并终止其中一个事务。
报错示例:Deadlock found when trying to get lock; try restarting transaction
排查方法:通过SHOW ENGINE INNODB STATUS查看死链详情;调整事务执行顺序,避免交叉加锁。

4、语法或兼容性问题
并行执行时,不同数据库版本或配置可能导致SQL语句行为差异,某些函数在分片环境下不支持跨节点调用。
典型错误:Function 'xxx' does not exist 或Syntax error in parallel execution
预防措施:统一开发环境与生产环境的数据库版本;测试阶段开启全量SQL审计。
**二、并行报错的系统性排查思路
1、日志分析:定位第一现场
数据库日志:关注error.log或slow_query.log中的时间戳、事务ID及报错堆栈。
应用日志:结合应用的上下文信息(如用户ID、请求参数)缩小排查范围。
2、执行计划检查:识别低效操作
使用EXPLAIN或EXPLAIN ANALYZE解析SQL执行计划,重点关注全表扫描、临时表、文件排序等高开销操作,未命中索引的大表JOIN可能因资源争用导致并行失败。
3、资源监控:实时追踪瓶颈
工具推荐:Prometheus+Grafana监控CPU、内存、I/O;
数据库内置视图:通过sys.schema_table_statistics分析表级资源消耗。
4、简化复现:最小化问题场景
通过剥离业务逻辑,构造最小化的SQL测试用例,在测试库中模拟高并发执行特定语句,验证报错是否可稳定复现。
**三、优化并行SQL的实践策略
1、索引设计:降低锁冲突概率
- 对高频更新的字段(如状态码)避免使用聚簇索引;
- 使用覆盖索引减少回表查询,缩短锁持有时间。
2、事务拆分:减少长事务风险
将大事务拆分为多个短事务,优先提交非关键操作,先记录日志再更新核心数据。
3、隔离级别调整:平衡一致性与性能
根据业务需求选择合适的隔离级别,若允许脏读,可降级为READ UNCOMMITTED以减少锁竞争。
4、超时与重试机制
- 设置合理的锁超时时间(如MySQL的innodb_lock_wait_timeout=5);
- 在应用层实现幂等重试,避免因短暂冲突导致业务中断。
5、压力测试:提前暴露隐患
使用sysbench或JMeter模拟高并发场景,验证数据库的并行处理极限。
**四、个人观点
并行执行中的SQL报错本质是资源竞争与协调机制的失衡,开发者需从“预防”和“治理”两个维度入手:一方面通过合理的设计降低冲突概率,另一方面建立快速响应的排查体系,在分布式架构普及的今天,理解数据库的并行原理比盲目调参更为重要,建议团队定期进行SQL代码评审,将并行兼容性纳入上线前检查清单,从源头规避风险。