在使用R语言进行数据分析或文档生成时,knitr作为一款强大的工具,能够将代码、文本与输出结果无缝整合,许多用户在尝试生成包含中文内容的文档时,常会遇到报错问题,本文将针对这一现象展开分析,并提供经过验证的解决方案,帮助开发者更高效地处理中文编码难题。
常见报错场景与核心原因

1、LaTeX编译失败
当通过knitr调用LaTeX引擎(如XeLaTeX或LuaLaTeX)编译.Rmd文件时,若文档包含中文,常会出现“Undefined control sequence”或“Font XXX not found”的错误提示,根源在于LaTeX默认未配置中文字体支持,且未正确声明文档编码类型。
2、PDF输出乱码
生成的PDF文件中,中文显示为空白方块或乱码字符,这通常由两个因素导致:
- R环境未正确设置系统语言编码
- PDF生成引擎未加载合适的中文字体包

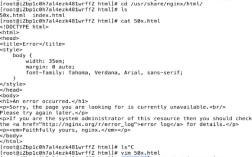
3、HTML文档渲染异常
在输出HTML文件时,浏览器可能无法正确解析中文字符,表现为页面显示问号或特殊符号,此时需检查HTML头部的字符集声明是否与文件实际编码一致。
针对性解决方案
场景一:LaTeX编译配置优化
在.Rmd文件的YAML头部添加以下配置:
header-includes:
- \usepackage{ctex}
- \setCJKmainfont{SimSun}
output:
pdf_document:
latex_engine: xelatex此配置通过ctex宏包自动处理中文排版,并指定系统已安装的中文字体(如示例中的宋体),若未安装特定字体,可替换为系统支持的字体名称,或通过tinytex::install_tinytex()安装完整TeX环境。

场景二:R全局环境设置
在R脚本开头添加环境参数设置:
Sys.setlocale(category = "LC_ALL", locale = "zh_CN.UTF-8") options(encoding = "UTF-8")
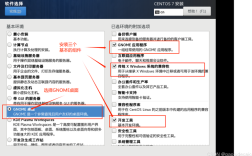
该设置将R会话的字符编码强制指定为UTF-8,确保控制台输出、文件读写操作均使用统一编码标准,对于Windows系统用户,建议将系统区域设置为“Beta版:使用Unicode UTF-8提供全球语言支持”(控制面板 > 区域设置)。
场景三:HTML输出字符集声明
在生成HTML文档时,确保YAML头部包含正确的元数据声明:
output:
html_document:
self_contained: true
meta: "charset=utf-8"同时检查生成HTML文件的<head>部分是否包含<meta charset="utf-8"/>标签,若使用自定义模板,需在模板文件中手动添加该标签。
进阶调试技巧
日志分析:当报错信息不明确时,可在R控制台执行knit("filename.Rmd")命令直接调用编译过程,观察实时输出的详细错误日志。
编码验证:用Notepad++或VS Code等编辑器打开源文件,确认右下角状态栏显示“UTF-8 without BOM”编码格式。
最小化测试:新建仅包含中文标题和简单段落的新.Rmd文件进行编译测试,排除其他代码段干扰。
预防性编码规范建议
1、统一使用UTF-8编码保存所有相关文件(包括.Rmd、.tex、.css等)
2、在RStudio中通过"Tools > Global Options > Code > Saving"设置默认文本编码为UTF-8
3、避免在代码注释或文本段落中混用全角/半角符号
4、定期更新rmarkdown、knitr及相关LaTeX套件至最新版本
个人认为,处理中文编码问题的关键在于建立标准化的开发环境,许多开发者习惯遇到报错后才开始搜索解决方案,预先配置好编码参数、选择合适的编译工具链,能节省大量调试时间,对于长期使用R Markdown进行中文文档创作的团队,建议编写统一的模板文件并封装常用配置,从根本上降低环境差异导致的兼容性问题,技术文档创作本质上是对细节的掌控——看似琐碎的编码设置,往往决定着工作流的顺畅程度。