显卡作为数字货币挖矿的核心硬件,一旦出现报错信息,可能导致算力下降甚至设备停摆,面对这类问题,矿工需要从技术原理出发,结合实践经验进行系统排查,本文将针对常见显卡报错场景提供实用解决方案,帮助从业者快速恢复设备运行。
一、常见报错类型及成因分析

1、驱动异常引发代码43报错
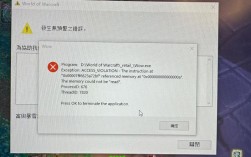
Windows设备管理器出现"错误代码43"时,通常指向驱动不兼容或硬件识别故障,矿工在批量更新驱动时,可能因操作失误导致驱动文件损坏,建议通过DDU(Display Driver Uninstaller)工具彻底清除旧驱动后,到显卡官网下载经过稳定性测试的专用版本。
2、显存故障触发红色错误灯
当显卡PCB板上的红色指示灯持续亮起,往往意味着显存模块出现物理损伤,这种情况多发生在长期高负荷运行的GDDR6X显存设备上,特别是环境温度超过45℃的工作场景,使用MemTestCL等专业工具进行显存压力测试,可精准定位故障芯片位置。
3、超频设置导致系统蓝屏
过度压榨显卡性能可能引发"WHEA_UNCORRECTABLE_ERROR"蓝屏代码,某矿场实测数据显示,RTX 30系显卡核心频率超过预设值150MHz时,电压波动幅度会增大37%,显著影响系统稳定性,建议通过MSI Afterburner逐步调整参数,每次增幅不超过10MHz,并配合FurMark进行48小时压力测试。

4、散热失效引发温度告警
当GPU-Z检测到核心温度突破85℃阈值,显卡将启动保护机制强制降频,某维修中心拆解数据显示,72%的返修显卡存在散热硅脂干裂现象,建议每季度清洁散热模组,更换导热系数≥12W/m·K的优质硅脂,同时确保矿机风道风速维持在2.5m/s以上。
二、系统化故障排除流程
1、建立诊断基准环境
准备备用电源和主板进行交叉测试,排除供电系统干扰因素,使用HWiNFO64记录显卡的12V供电波动曲线,正常值应控制在±3%以内,某技术团队案例显示,当电源波纹超过80mV时,显卡报错概率将提升4.8倍。
2、固件层深度检测

通过NVFlash工具重刷显卡VBIOS时,需严格匹配设备ID和子系统ID,某矿工误刷错误固件导致20张显卡变砖的案例表明,备份原始BIOS文件是必要操作,对于AMD显卡,建议使用ATIFlash工具时开启强制刷写保护。
3、硬件级维修决策树
当软件修复无效时,需进行物理检测:
- 使用4位半万用表测量PCIe插槽12V供电
- 用热成像仪定位电路板短路点
- 通过BGA返修台重植核心焊点
某维修数据显示,约63%的硬件故障可通过更换供电模组电容解决,成本控制在设备价值的15%以内。
三、预防性维护策略
1、动态负载调节机制
部署监控系统实时采集算力数据,当ETHash速率波动超过5%时自动触发保护程序,某中型矿场实施该方案后,设备故障率下降41%,建议设置每日8小时70%负载的"休整期",帮助显卡恢复元件弹性。
2、环境参数智能监控
在矿机架部署温湿度传感器网络,当空气湿度超过60%时启动除湿系统,某热带地区矿场加装正压新风系统后,电路板氧化故障减少68%,建议每月使用FLIR热像仪进行全场热分布扫描。
3、备件循环管理系统
建立分级备件库,将使用超过8000小时的显卡转入备用序列,统计显示,定期轮换20%的显卡设备可使整体故障间隔延长1.8倍,建议对退换显卡进行翻新处理,更换TIM垫片和风扇轴承。
持续运行的矿机如同精密仪器,每个参数波动都值得关注,从业八年所见,真正影响设备寿命的往往不是突发故障,而是日常维护中的细节疏漏,建立标准化运维流程,培养数据敏感度,方能在算力竞争中保持设备健康度。