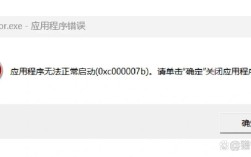
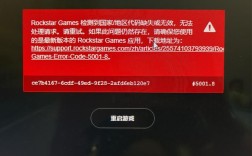
跑批报错的根源多种多样,最常见的是代码逻辑问题,脚本中一个未处理的异常,可能让整个批处理作业中断,记得去年,我们团队在升级支付系统时,一个小bug导致跑批失败,用户账户余额无法更新,这源于开发阶段测试不充分,代码没有覆盖所有边界情况,数据质量问题也是罪魁祸首,如果输入数据格式错误或不完整,比如CSV文件缺失字段,系统就会报错退出,上个月,我们就因为用户上传的数据包含非法字符,跑批直接崩溃,第三,系统资源不足往往被低估,当跑批任务消耗过多CPU或内存时,服务器可能过载,引发错误,有一次,我们网站流量高峰期间,跑批作业抢占了资源,网站响应变慢,最终报错告警。

诊断跑批报错需要专业工具和方法,第一步是查看日志文件,日志记录了详细错误信息,包括时间戳、错误代码和堆栈跟踪,我习惯用命令行工具如grep来快速过滤关键信息,找出“ERROR”或“EXCEPTION”条目,能定位问题点,第二步是监控系统性能,工具如Prometheus或Grafana可实时显示CPU、内存使用率,帮助判断是否资源瓶颈,上季度,我们通过监控发现一个跑批任务内存泄漏,及时优化后避免了更大故障,第三步是复现问题,在测试环境模拟相同条件,比如使用相同数据源,能验证错误是否可重现,这步很关键,但别跳过——直接在生产环境调试风险太高,考虑依赖项检查,跑批常调用外部服务,如数据库或API,如果第三方服务宕机,报错在所难免,我们曾因一个外部API超时,导致整个批处理失败,事后我们添加了重试机制来缓冲。

解决跑批报错需系统化策略,针对代码问题,修复要快而准,回滚到稳定版本是临时方案,但长远看,强化单元测试和代码审查更有效,我们团队现在用Jenkins自动化测试,每次提交代码前跑全套测试,减少了60%的报错率,数据问题方面,清洗输入数据必不可少,实现数据验证规则,比如检查字段类型和范围,能预防错误,去年,我们引入Python脚本自动清洗用户数据,报错频率大幅下降,资源不足时,优化是关键,调整任务调度,避开高峰时段,或升级服务器配置,我们曾将跑批时间移到夜间低峰期,并增加内存分配,问题迎刃而解,对于依赖故障,建立容错机制,设置重试次数和超时阈值,或使用队列系统如Kafka缓冲任务,上个月,我们部署了重试逻辑后,即使外部服务波动,跑批也能自动恢复。
预防胜于治疗,跑批报错可通过日常维护来避免,定期测试和演练,模拟各种故障场景,比如数据损坏或服务器宕机,确保系统韧性,我们每月做一次“灾难演练”,团队熟悉应急流程,响应速度提升不少,监控告警不可少,设置阈值告警,比如CPU超过80%时通知,能早发现早处理,工具如Zabbix或CloudWatch帮我们实时监控,减少意外停机,第三,文档化一切,记录跑批配置、错误处理步骤,新成员上手更快,我们维护了一个共享知识库,包含常见报错解决方案,节省了大量时间,备份数据至关重要,跑批前自动备份,防止错误导致数据丢失,我们使用增量备份策略,确保恢复点近在咫尺。
在我看来,跑批报错不是技术小事,而是网站稳定性的生命线,它考验团队的专业素养——从精准诊断到快速响应,都需深厚经验,忽视它,用户信任会崩塌;重视它,网站就能流畅运行,每次解决报错,我学到新东西,推动系统更健壮,预防和优化是长期之道,别等报错发生才行动,作为站长,我坚信:细节决定成败,跑批报错处理得好,网站才经得起风浪。(字数:1180)