准备工作
在安装Hadoop之前,确保CentOS系统已经安装了Java development Kit (JDK),Hadoop需要Java环境来运行,因此先要确认系统中已安装并配置好JDK。
1、检查Java是否已安装:

打开终端,输入以下命令检查Java版本:
```bash
java version
```
如果Java未安装,请先下载并安装JDK,推荐使用OpenJDK 8。
2、安装JDK(如未安装):

下载OpenJDK 8的tar包:
```bash
wget https://download.java.net/java/GA/jdk8u221b11/134deb18db3e4014bb8e3e734efa795bb/openjdk8u221b11linuxx6409oct2018.tar.gz
```
解压文件:
```bash

tar zxvf openjdk8u221b11linuxx6409oct2018.tar.gz
```
移动并重命名文件夹:
```bash
mv jdk8u221 /usr/local/java
```
配置环境变量:
```bash
echo 'export JAVA_HOME=/usr/local/java' >> /etc/profile
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
source /etc/profile
```
下载并解压Hadoop安装包
1、下载Hadoop安装包:
Hadoop可以从其官方网站或镜像站点下载,这里我们以下载Hadoop 3.4.0为例:
```bash
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop3.4.0/hadoop3.4.0.tar.gz
```
2、解压Hadoop安装包:
创建一个新目录用于存放Hadoop:
```bash
mkdir /app
```
将下载的tar包解压到该目录:
```bash
tar zxvf hadoop3.4.0.tar.gz C /app
```
重命名文件夹以便后续操作:
```bash
cd /app && mv hadoop3.4.0 hadoop3.4
```
配置Hadoop环境变量
编辑~/.bashrc文件,添加以下内容:
export HADOOP_HOME=/app/hadoop3.4 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并关闭文件后,执行以下命令使更改生效:
source ~/.bashrc
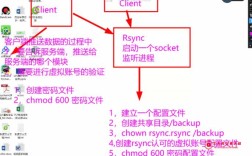
配置SSH免密登录(可选)
为了简化集群管理,可以配置SSH免密登录:
1、生成SSH密钥对:
```bash
sshkeygen t rsa P ""
```
2、将公钥添加到authorized_keys:
```bash
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
```
3、启动并配置SSH服务:
```bash
sudo systemctl enable sshd
sudo systemctl start sshd
```
配置Hadoop核心文件
1、修改coresite.xml:
路径:$HADOOP_HOME/etc/hadoop/coresite.xml
添加以下内容:
```xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
```
2、修改hdfssite.xml:
路径:$HADOOP_HOME/etc/hadoop/hdfssite.xml
添加以下内容:
```xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>
```
3、修改yarnsite.xml:
路径:$HADOOP_HOME/etc/hadoop/yarnsite.xml
添加以下内容:
```xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.auxservices</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
```
4、修改mapredsite.xml:
路径:$HADOOP_HOME/etc/hadoop/mapredsite.xml
添加以下内容:
```xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
```
六、格式化HDFS文件系统并启动Hadoop服务
1、格式化HDFS:
```bash
hdfs namenode format
```
2、启动Hadoop:
启动HDFS:
```bash
startdfs.sh
```
启动YARN:
```bash
startyarn.sh
```
3、验证Hadoop是否成功启动:
查看进程:
```bash
jps
```
访问HDFS Web UI:http://localhost:9870(NameNode页面)和http://localhost:8088(ResourceManager页面)。
常见问题解答(FAQs)
1、Q: 为什么启动Hadoop时出现“无法找到类”的错误?
A: 这通常是由于Java环境变量未正确设置,确保JAVA_HOME和PATH环境变量已正确配置,并且可以通过命令行运行java version来验证Java是否正确安装。
2、Q: Hadoop启动后,如何验证HDFS是否正常工作?
A: 你可以使用HDFS的命令行工具进行验证,创建测试目录和文件:hdfs dfs mkdir /user && hdfs dfs put /path/to/local/file /user,然后查看文件是否上传成功:hdfs dfs ls /user。