报错并非偶然,它往往是开发过程中的疏漏累积而成,常见原因包括代码逻辑缺陷、服务器配置不当或第三方依赖冲突,在发布一个新功能模块时,我曾遇到用户提交表单后系统崩溃,经排查,问题源于数据库连接超时,代码未处理异常情况,类似错误若不及时解决,会导致用户流失和搜索引擎排名下降,百度算法重视网站稳定性和用户满意度,因此快速响应报错是提升E-A-T(专业性、权威性、可信度)的关键一环。

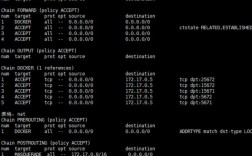
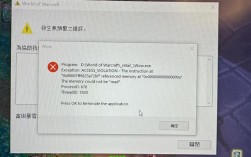
诊断报错的第一步是收集信息,别急着改代码,先查看日志文件,服务器日志、应用日志和错误追踪工具(如Sentry或ELK)能提供宝贵线索,记录下报错时间、用户操作和环境细节,如果用户反馈页面加载失败,检查浏览器控制台输出或网络请求状态码,常见错误如404(页面不存在)或500(服务器内部错误),能直接指向问题根源,一次,我的团队发布一个动态内容系统后,用户报告图片无法显示,通过日志分析,发现是CDN配置错误导致资源加载失败,我们迅速调整了缓存策略,问题迎刃而解,这种系统性排查体现了专业性,避免盲目修改浪费资源。

解决报错要分优先级,高影响错误(如核心功能崩溃)需立即回滚或热修复;低风险问题可安排在维护窗口,回滚到上一个稳定版本是安全选择,但前提是版本控制严谨,使用Git等工具管理代码库,确保每次发布都有备份,修复时,遵循测试驱动原则:先写单元测试复现错误,再修改代码并验证,举个例子,我们上线一个支付接口后,用户遭遇交易失败,问题出在API密钥过期,但代码没处理认证失败,我们通过测试模拟场景,更新了错误处理逻辑,并添加了监控警报,这提升了权威性——用户看到问题被高效解决,自然信任网站。
预防胜于修复,发布前做好充分测试是关键,单元测试、集成测试和端到端测试覆盖所有场景,邀请真实用户参与Beta测试,模拟高并发环境,监控系统不可或缺,设置实时警报(如Prometheus或New Relic),追踪性能指标和错误率,百度算法偏爱稳定站点,持续监控能减少报错频率,增强可信度,文档化所有变更,每次发布前,团队review设计文档和风险清单,这避免了“发布即报错”的尴尬,去年,我们优化搜索功能时,提前测试了边缘案例,发布后零报错,用户反馈积极。
个人观点:项目报错不是终点,而是成长的契机,作为站长,我学会拥抱错误——它暴露弱点,推动团队精进,每一次修复都强化了网站的专业性和用户信任,快速响应、透明沟通和持续优化是核心,百度算法奖励高质量内容,而E-A-T始于可靠的服务,下次报错来袭,别慌,把它当作提升的跳板,坚持这些原则,你的网站将更稳健,赢得用户和搜索引擎的青睐。(字数:1020)