提取PDF文件中的文字是一个常见且重要的任务,特别是在处理大量数据、进行数据分析或重新发布文档内容时,以下是几种有效的方法,从简单的复制粘贴到使用高级的OCR技术和编程接口,满足不同用户的需求。
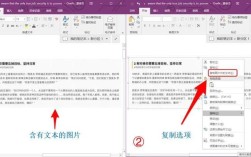
一、直接复制法
1、步骤:打开PDF文件,选中所需内容,右键选择“复制”,打开文本编辑器或文字处理软件(如Microsoft Word或Google Docs),右键选择“粘贴”,将复制的文本粘贴到文本编辑器中。

2、优点:操作简单,适合少量文本提取。
3、缺点:仅适用于非加密且结构不复杂的PDF文件,容易出错。
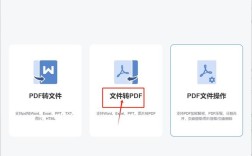
二、PDF转Word法
1、步骤:打开小圆象PDF转换器或其他在线PDF转换工具,选择“PDF转Word”功能,添加文件后点击“转换下载”。
2、优点:操作简便,支持多种格式转换。
3、缺点:转换后的格式可能需要进一步调整。
三、另存为TXT格式
1、步骤:打开PDF软件,点击“文件”>“打开”,找到要提取文字的PDF文档并打开,点击“文件”>“另存为”,在弹出的窗口中选择“txt”格式,点击“保存”按钮,进入文档保存的目录,双击打开TXT文件查看文字内容。

2、优点:简单快捷,适用于大多数PDF文件。
3、缺点:无法保留原始格式。
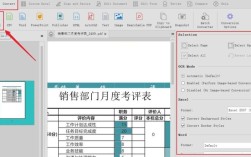
四、使用OCR技术
1、步骤:打开PDF文字识别软件,导入PDF文件,点击“OCR文字识别”按钮,圈选需要识别的文字区域,执行“识别”>“开始识别”,检查识别结果并进行修正,导出识别结果,选择输出格式(如TXT、RTF等)。
2、优点:可以识别扫描件中的文字,适用范围广。
3、缺点:需要额外的OCR软件,可能需付费。
五、在线PDF工具
1、步骤:上传PDF文件到在线PDF转换器(如ComPDFKit),自定义转换属性(如OCR、输出格式等),点击“转换”按钮,下载转换后的文件。

2、优点:无需安装软件,操作简便,支持多种输出格式。
3、缺点:依赖网络连接,可能存在隐私和安全问题。
六、离线PDF软件
1、步骤:打开PDF阅读器或编辑器(如PDF Reader Pro),打开包含要提取文本的PDF文档,单击并拖动以选择所需文本,右键选择“复制”,打开文本编辑器或文字处理软件,粘贴复制的文本。
2、优点:适合少量文本提取,操作简单。
3、缺点:不适合批量或频繁的文本提取任务。
七、使用PDF SDK
1、步骤:创建新项目并安装ComPDFKit PDF库,应用许可证,确保获得适当的授权,实现文本提取代码,根据编程语言和平台编写相应的代码。
2、优点:高度灵活,可定制化强,适合开发人员使用。
3、缺点:需要编程知识,开发成本较高。
通过以上几种方法,用户可以根据自己的需求和技术水平选择合适的方式来提取PDF文件中的文字,无论是简单的复制粘贴,还是利用OCR技术和编程接口,都能有效地解决这一常见问题。