在Python编程中,decode()方法用于将字节串转换成字符串,在使用这个方法时,经常会遇到报错问题,以下是关于Python decode报错的详细分析与解决方案:
1、错误原因

文件编码不一致:当你尝试用UTF8编码读取一个实际上使用其他编码(如ISO88591或GBK)的文件时,会引发UnicodeDecodeError。
混合编码:文件中混合了多种编码格式的字符,导致解码失败。
网络数据流:从网络接收的数据流可能不是UTF8编码,直接解码时会引发错误。
2、常见报错类型
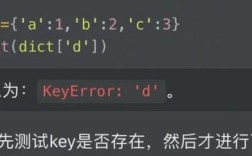
UnicodeDecodeError:这是最常见的一种报错,提示无法解码某个字节。UnicodeDecodeError: 'utf8' codec can't decode byte 0xXX in position Y: invalid start byte。
AttributeError:在Python 3中,如果对已经是字符串的对象调用decode()方法,会报AttributeError: 'str' object has no attribute 'decode'。

3、解决方法
确定文件编码:使用工具如chardet来检测文件编码。
```python
import chardet
with open('example.txt', 'rb') as f:
result = chardet.detect(f.read())

print(result['encoding'])
```
使用正确的编码读取文件:一旦知道了文件的编码,就可以使用正确的编码参数来打开文件。
```python
encoding = 'iso88591' # 假设检测到的编码是ISO88591
with open('example.txt', 'r', encoding=encoding) as f:
content = f.read()
```
忽略错误编码的字符:如果你不想或不能确定文件的编码,可以选择忽略那些无法解码的字符。
```python
with open('example.txt', 'r', encoding='utf8', errors='ignore') as f:
content = f.read()
```
替换错误编码的字符:另一种方法是替换那些无法解码的字符,而不是忽略它们。
```python
with open('example.txt', 'r', encoding='utf8', errors='replace') as f:
content = f.read()
```
4、具体代码示例
读取GBK编码文件:
```python
with open('filename', 'r', encoding='gbk') as f:
content = f.read()
print(content)
```
处理网络数据流:
```python
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('www.example.com', 80))
data = s.recv(1024)
print(data.decode('utf8', errors='ignore'))
```
避免在Python 3中使用str.decode():在Python 3中,字符串已经是Unicode,不需要再进行decode操作。
```python
text = 'Hello, World!'
encoded_text = text.encode('utf8')
print(encoded_text) # 输出:b'Hello, World!'
decoded_text = encoded_text.decode('utf8')
print(decoded_text) # 输出:Hello, World!
```
相关问答FAQs
1、为什么在Python 3中对字符串调用decode()会报错?
在Python 3中,字符串默认已经是Unicode编码,因此不需要再进行decode操作,如果你对字符串调用decode()方法,会报AttributeError: 'str' object has no attribute 'decode',正确的做法是对字节串调用decode()方法,byte_string.decode('utf8')。
2、如何检测文件的编码格式?
你可以使用第三方库chardet来自动检测文件的编码格式,首先安装chardet库,然后使用它来检测文件的编码:
```python
import chardet
with open('example.txt', 'rb') as f:
result = chardet.detect(f.read())
print(result['encoding']) # 打印检测到的编码
```
通过以上内容,可以有效解决Python decode报错的问题,并确保程序能够正确处理不同编码的文本数据。