在处理“报错faceswap”这一主题时,首先需要了解Faceswap是什么,Faceswap是一个开源的深度学习工具,主要用于交换图片或视频中的人脸,它使用Python编程语言和TensorFlow框架,允许用户通过训练模型来识别和替换人脸。
常见错误及解决方法

1. 安装错误
问题描述: 在安装Faceswap时可能会遇到依赖性问题或者环境配置问题。
解决方法: 确保Python版本正确(推荐使用Python 3.6以上版本),并且使用虚拟环境隔离项目依赖,使用pip安装所有必要的库,如tensorflow, keras等。
2. 训练错误
问题描述: 在训练模型时可能会遇到收敛问题或者过拟合。
解决方法: 调整学习率,增加数据增强,使用正则化技巧如dropout,以及早停法来避免过拟合。

3. 性能问题
问题描述: 模型运行缓慢,消耗资源过多。
解决方法: 优化代码,使用更快的硬件(如GPU加速),减少输入数据的分辨率,或者使用更小的模型架构。
4. 模型泛化能力差
问题描述: 模型在训练集上表现良好,但在新数据上表现不佳。
解决方法: 收集更多的训练数据,特别是多样化的数据,以增强模型的泛化能力,同时可以尝试使用数据增强技术来人为地扩展训练数据集。

5. 保存和加载模型问题
问题描述: 无法正确保存或加载训练好的模型。
解决方法: 确保使用正确的API进行模型的保存和加载,使用model.save()和keras.models.load_model(),检查文件路径和名称是否正确。
6. 预测错误
问题描述: 在实际应用中,模型的预测结果与预期不符。
解决方法: 检查输入数据是否经过了与训练数据相同的预处理步骤,确保输入数据的格式和范围与训练时一致。
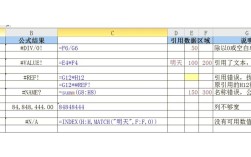
表格:错误类型与解决策略
| 错误类型 | 问题描述 | 解决方法 |
| 安装错误 | 依赖性或环境配置问题 | 确保Python版本正确,使用虚拟环境,pip安装依赖 |
| 训练错误 | 收敛或过拟合问题 | 调整学习率,数据增强,使用dropout和早停法 |
| 性能问题 | 运行缓慢,资源消耗大 | 优化代码,使用GPU,减少输入分辨率,使用更小的模型 |
| 泛化能力差 | 在新数据上表现不佳 | 收集更多数据,使用数据增强 |
| 保存加载问题 | 无法保存或加载模型 | 使用正确的API,检查文件路径和名称 |
| 预测错误 | 预测结果与预期不符 | 检查输入数据的预处理和格式 |
FAQs
Q1: 如果我在训练过程中遇到NaN值怎么办?
A1: NaN值通常表示计算过程中出现了未定义的操作,如除以零或对负数取平方根,首先检查你的数据是否有异常值,尝试降低学习率,因为过高的学习率可能导致梯度爆炸,确保模型初始化得当,不当的初始化也可能导致NaN值。
Q2: 我如何知道我的模型是否过拟合?
A2: 过拟合通常表现为模型在训练集上的准确率远高于验证集或测试集的准确率,你可以通过绘制训练集和验证集的损失曲线来观察,如果验证集的损失明显高于训练集的损失,且差距随时间增大,那么很可能是过拟合,此时应该考虑增加正则化、使用dropout或收集更多数据来解决过拟合问题。