CentOS Oracle 乱码?别慌,咱一起搞定它!
宝子们,是不是在用 CentOS 搭配 Oracle 数据库的时候,遇到过那让人头疼的乱码问题😣?看着数据库里那些乱七八糟、不成样子的字符,心里是不是特别着急,不知道该从哪儿下手解决?别担心哈,今儿咱就好好唠唠这事儿,把这个问题给掰扯清楚咯。

一、为啥会有乱码这烦人精出现呢🧐
咱先得搞明白,这乱码到底是咋冒出来的,其实啊,这主要就是因为字符编码不一致闹的,就好比两个人说不同语言,鸡同鸭讲,肯定听不懂呀,CentOS 系统和 Oracle 数据库,它们各自都有默认的字符编码设置,要是这两边的编码对不上,那数据一交互,可不得乱成一锅粥嘛,比如说,系统这边用的是 UTF8 编码,数据库那边却整了个 ISO88591 啥的,这不就乱了套咯。
还有啊,有时候咱们从别的地方导入数据,像从 Windows 系统导过来的,它原本的编码格式可能跟咱们 Linux 下的 CentOS 系统不匹配,这一倒腾,乱码也就跟着来了,就像你从外地搬来一堆东西,结果发现包装箱上的字你都不认识,懵圈了吧😉
二、怎么瞅出是啥编码在捣鬼呢👀
咱得学会看看系统和数据库现在用的是啥编码,这样才能对症下药嘛。
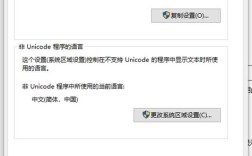
对于 CentOS 有个简单法子,咱打开终端,输入这么个命令“locale”,敲完回车,就会出来一堆信息,这里面就有系统当前的语言和编码设置啦,像“LANG=en_US.UTF8”这类的,就说明系统这会儿用的是 UTF8 编码哦,要是看到不是咱想要的编码,那可能就是问题所在咯。

再看看 Oracle 数据库这边哈,咱登录到数据库里,执行这么一条 SQL 语句:“SELECT parameter,value FROM nls_database”,这一查,就能看到数据库的各种 NLS(国家语言支持)参数设置啦,其中像“NLS_CHARACTERSET”这个参数的值就是数据库的字符集编码咯,要是发现它和系统编码不一样,那大概率就是这俩家伙没对上,才导致乱码的。
三、怎么解决这乱码的大麻烦呢😎
知道病因了,那就好办多啦,咱这就动手解决问题。
(一)改系统编码
如果发现是系统编码不太对,咱可以试着把它改成跟 Oracle 数据库匹配的编码,不过这操作得小心点儿哈,毕竟系统编码一动,好多东西可能都会受影响呢,咱还是先备份好重要数据,以防万一嘛。
在 CentOS 系统里,修改编码可以通过修改配置文件来实现,比如说“/etc/locale.conf”这个文件,咱用文本编辑器打开它,把里面的“LANG”那一行改成想要的编码格式,像“LANG=zh_CN.UTF8”,然后保存退出,接着再重启一下系统,让设置生效,这样系统编码就变过来啦😃。
(二)调数据库编码
要是觉得改系统编码太麻烦或者怕出问题,那咱也可以只改数据库这边的编码,在 Oracle 数据库里,改变编码需要一些步骤哦。

首先得导出数据,咱用“expdp”工具把数据库里的数据导出来,在执行命令的时候,可以加上“encoding=utf8”这样的参数,指定一下导出数据的编码格式为 UTF8,等数据导出来之后呢,再把数据库的字符集改成咱想要的编码,这得通过一些 DDL 语句来操作,ALTER DATABASE CHARACTER SET utf8;”之类的语句(这里只是举个例子,具体语句得根据实际数据库版本和情况来写哈),改完之后,再用“impdp”工具把刚才导出来的数据导入回去,同样加上对应的编码参数,这样数据库编码也就调整好啦。
(三)处理导入数据的乱码
要是只有导入的数据有乱码问题,那咱可以在导入的时候顺便把编码给转换一下,有些导入工具是有编码转换功能的,咱找找看有没有这个选项,选上正确的源编码和目标编码,这样导入的数据就不会是乱码啦,要是没有这个功能,也别急,咱可以先用一些文本处理工具先把数据文件的编码转换好了,再拿去导入数据库就行咯。
四、预防乱码的小妙招🤗
咱可不能老是等乱码出现了再去解决,还得有点预防意识不是,以后在装软件、导数据啥的之前,都先留意一下它们的编码设置,尽量保证系统、数据库、导入导出的数据都是用的同一种编码格式,这样就能少很多麻烦事儿啦,而且啊,定期检查一下系统和数据库的编码设置,要是发现有啥不对劲的地方,赶紧调整过来,防患于未然嘛。
其实啊,遇到 CentOS 下 Oracle 乱码这个问题,真没啥可怕的,咱只要搞清楚原因,按照正确的方法去解决,很快就能让数据库里的字符都乖乖听话,变得整整齐齐的啦😁,希望咱今天聊的这些,能帮到正在被乱码困扰的宝子们哈,以后再碰到这问题,就照着咱说的试试,肯定能搞定哒👍!