解决CentOS无法识别存储设备的深度排查指南
场景重现: 你为服务器插入了崭新的硬盘或连接了可靠的存储阵列,信心满满地登录CentOS执行 lsblk 或 fdisk -l,期待中的设备名称(如 /dev/sdb、/dev/sdc)并未出现,命令行界面一片沉寂,存储空间未增加分毫——CentOS未能识别新存储,这种状况会直接导致业务停滞,数据无法存取。
问题根源深度剖析:

物理层连接故障(最基础也最易忽视):
- 线缆问题: SATA/SAS数据线或电源线松动、损坏、接触不良是最常见的原因,劣质线缆或反复插拔导致的内部断裂难以目测发现。
- 端口/背板故障: 服务器硬盘背板上的特定端口损坏,或主板SATA/SAS控制器端口故障。
- 设备兼容性/供电不足: 特别是使用大容量硬盘或多盘位硬盘笼时,电源功率不足或硬盘与控制器兼容性不佳(常见于较老硬件使用新型大容量盘)。
硬件识别层问题(HBA/RAID卡):
- 未正确识别控制器: 服务器使用的独立HBA(主机总线适配器)或RAID卡未被系统内核识别,执行
lspci -vvv | grep -i storage或lspci -vvv | grep -i sas查看设备是否列出及驱动状态 (Kernel driver in use是否正常)。 - 驱动程序缺失/不匹配: 这是关键环节,CentOS内核可能未内置适配你的HBA/RAID卡型号的驱动,或内置驱动版本过旧存在兼容性问题。
dmesg | grep -i error或dmesg | grep -i <控制器厂商名>常能发现驱动加载失败的线索(如failed to load,unknown symbol等)。 - RAID卡配置未初始化/未导入: 对于RAID卡,新配置的虚拟磁盘(Virtual Drive)可能未执行初始化操作,或已存在配置(如从其他机器移入)未正确导入(Foreign Configuration Import)。
- 未正确识别控制器: 服务器使用的独立HBA(主机总线适配器)或RAID卡未被系统内核识别,执行
操作系统内核与设备管理层:
- 总线未重新扫描: 系统在启动后添加的硬盘,有时需要手动触发SCSI或SAS总线重新扫描才能被识别。
echo "- - -" > /sys/class/scsi_host/hostX/scan是常用方法(X需替换为实际主机号)。 - 内核模块未加载/冲突: 必需的存储驱动内核模块(如
megaraid_sas,mpt3sas,hpsa,ahci等)未加载 (lsmod | grep <模块名>),或存在冲突模块被加载。 - 设备映射问题(多路径/udev): 复杂的存储环境(如SAN)中,多路径软件配置错误可能导致设备未能正确映射到本地。
/etc/udev/rules.d/下的自定义规则错误也可能干扰设备识别。 - 损坏的 initramfs: 初始RAM文件系统 (initramfs) 包含了早期启动所需的驱动和模块,若其损坏或未包含当前存储控制器驱动,系统在引导阶段就无法识别存储,执行
dracut -v -f可尝试重建。 - 文件系统/分区表损坏(极端情况): 存储设备本身的分区表或文件系统严重损坏,可能导致内核拒绝识别或挂载,但通常仍能在
dmesg或lsblk中看到原始设备名(如/dev/sdX存在但无分区)。
- 总线未重新扫描: 系统在启动后添加的硬盘,有时需要手动触发SCSI或SAS总线重新扫描才能被识别。
专业级解决步骤:
基础物理检查(不可跳过):
- 彻底断电服务器(非重启)。
- 检查硬盘、HBA/RAID卡、所有相关线缆(数据线、电源线、SFF线缆)的连接是否牢固无松动,尝试更换线缆和端口。
- 确认硬盘指示灯状态(常亮、闪烁、不亮?),尝试将硬盘插入已知正常的槽位。
- 如有可能,在服务器BIOS/UEFI或HBA/RAID卡的配置界面(启动时按提示键进入,如
Ctrl+Rfor MegaRAID,F8for HP Smart Array)中,检查物理硬盘是否被控制器识别,这是区分物理层问题和OS层问题的关键点。
系统日志诊断(核心手段):

dmesg: 执行dmesg -T | grep -iE 'scsi|sata|sas|ata|error|fail|warn|disk|sd',仔细查看硬盘插入前后时间点的输出,寻找错误、警告、设备探测信息或驱动加载失败的记录,时间戳 (-T) 对定位问题发生时刻非常有用。/var/log/messages: 查看系统主日志文件tail -n 100 /var/log/messages或journalctl -b -p err..alert(Systemd系统),同样聚焦存储相关错误。lspci:lspci -vvv | grep -i storage确认存储控制器是否被系统PCI总线识别,并检查其驱动状态 (Kernel driver in use和Kernel modules)。
驱动与内核模块操作:
- 检查已加载模块:
lsmod | grep -iE 'megaraid|mpt|hpsa|ahci|raid'查看关键存储驱动是否加载。 - 尝试加载模块: 如未加载,使用
modprobe <模块名>手动加载(如modprobe megaraid_sas),观察dmesg输出是否有错误。 - 更新驱动: 如在日志中发现驱动错误或不匹配,需从硬件厂商官网下载适用于你的CentOS版本和内核版本的最新驱动,通常为
.rpm或提供编译指导的源码包,安装后重建 initramfs (dracut -v -f) 并重启。务必严格遵循厂商文档。
- 检查已加载模块:
触发总线重新扫描:
- 找出SCSI主机号:
ls /sys/class/scsi_host/(输出如host0,host1...)。 - 对每个主机执行扫描:
for host in /sys/class/scsi_host/host*/scan; do echo "- - -" > $host; done。 - 再次检查
lsblk或fdisk -l。
- 找出SCSI主机号:
处理RAID卡配置:
- 进入RAID卡管理界面(如MegaCLI,
storcli,hpssacli)。 - 检查物理盘状态:
<command> /cX show(查看是否在线/识别)。 - 检查虚拟磁盘:
<command> /cX/vY show(查看是否处于Optl状态),新配置需初始化(<command> /cX/vY start init),外来配置需导入(<command> /cX import)。
- 进入RAID卡管理界面(如MegaCLI,
重建 initramfs 并重启:
- 在执行了驱动安装、模块更改等操作后,必须:
dracut -v -freboot,这是确保更改在下次启动生效的关键。
- 在执行了驱动安装、模块更改等操作后,必须:
检查多路径与udev规则(SAN/复杂环境):
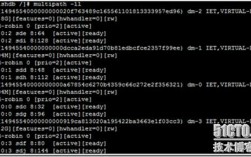
- 检查多路径软件状态:
multipath -ll(如果已安装配置)。 - 检查
/etc/udev/rules.d/下是否有自定义存储规则,暂时移走测试。
- 检查多路径软件状态:
预防与最佳实践:

- 硬件兼容性清单: 采购服务器和存储组件前,务必查阅硬件厂商(服务器厂商、HBA/RAID卡厂商、硬盘厂商)提供的官方兼容性列表(Compatibility List),明确支持的操作系统及版本。
- 固件更新: 定期检查并更新服务器BIOS、HBA/RAID卡固件、硬盘固件至推荐版本,固件修复常解决兼容性和稳定性问题。
- 驱动维护: 在CentOS生命周期内,关注存储控制器厂商发布的最新驱动更新,尤其在升级内核后,通过
yum update或厂商仓库更新。 - 标准化操作: 在线添加硬盘后养成执行
rescan-scsi-bus.sh(需安装sg3_utils包) 或手动扫描总线的习惯。 - 监控与日志: 部署完善的系统监控(如Zabbix, Nagios)和日志集中分析(如ELK Stack),设置针对存储错误日志的告警,实现主动发现问题。
遇到CentOS不识别存储,保持冷静,严格遵循从物理到逻辑、从底层到上层的排查路径,物理连接和控制器驱动状态是首要突破口,dmesg 日志则是诊断的核心依据,在关键生产环境操作前,务必在测试环境验证或制定完备的回滚计划,可靠存储是系统基石,其稳定识别需要持续关注硬件兼容性、驱动更新与规范运维。
观点: 对于关键业务服务器,建议在硬件选型阶段就将存储控制器兼容性作为首要考量,选择主流厂商且被目标CentOS版本良好支持的方案,在线添加存储后未能识别的情况虽然常见,但规范的操作流程(如主动扫描总线)可以避免大量不必要的故障排除时间。