训练模型是机器学习中至关重要的一步,它涉及到从数据准备到模型部署的多个环节,以下是详细的步骤和注意事项:
一、数据探索性分析(EDA)
1、查看数据分布:了解数据的基本情况,如均值、方差、最大值、最小值等。

2、缺失值处理:识别并处理数据集中的缺失值,可以通过填充、删除或插补等方式。
3、异常值检测:识别并处理异常值,避免它们对模型造成不良影响。
4、特征值分布:分析各个特征的分布情况,了解特征之间的关系。
5、正负样本比例:检查目标变量的正负样本比例,确保模型不会偏向于某一类。
6、相关性分析:分析特征之间的相关性,避免多重共线性问题。
二、数据预处理
1、缺失值处理:使用填充、删除或插补等方法处理缺失值。

2、异常值处理:通过标准化、归一化或使用特定算法(如IQR法)处理异常值。
3、类别数据编码:将类别型特征转换为数值型,常用的方法有独热编码(OneHot Encoding)和标签编码(Label Encoding)。
4、数据归一化/标准化:将数据缩放到同一范围,提高算法的收敛速度和准确性。
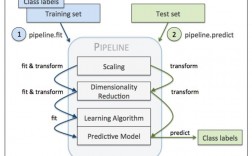
三、数据集划分
1、训练集:用于训练模型,占总数据的大部分(如70%80%)。
2、验证集:用于评估模型性能和调整参数,通常占10%15%。
3、测试集:用于最终评估模型的性能,不参与训练过程,通常占10%15%。

四、模型选择与超参数调整
1、选择合适的模型:根据任务类型(分类、回归、聚类)和数据特性选择合适的模型。
2、超参数调整:使用网格搜索(Grid Search)或随机搜索(Random Search)等方法寻找最佳超参数组合。
3、交叉验证:通过K折交叉验证等方法评估模型的稳定性和泛化能力。
五、模型训练
1、训练模型:使用训练集数据训练模型,并通过验证集评估模型性能。
2、避免过拟合:使用正则化、早停(Early Stopping)、数据增强等技术防止过拟合。
六、模型评估与优化
1、评估指标:选择合适的评估指标(如准确率、精确率、召回率、F1分数等)评估模型性能。
2、模型优化:根据评估结果调整模型结构、超参数或进行特征工程等优化操作。
七、模型部署与应用
1、模型保存:将训练好的模型保存为文件,以便在生产环境中加载和使用。
2、实时预测:根据应用需求实现批量预测或实时预测功能。
3、监控与更新:定期监控模型性能并根据新数据更新模型以保持其准确性。
八、相关问答FAQs
Q1: 在训练模型时,如何选择合适的机器学习库?
A1: 选择合适的机器学习库取决于项目的规模和复杂性,对于初学者和中小型项目,Scikitlearn是一个简单易用的库;对于深度学习项目,TensorFlow和PyTorch是目前最流行的两个库,它们功能强大且适用于大规模分布式计算,在选择时,还需要考虑社区支持、文档丰富程度以及团队成员的经验水平。
Q2: 如何评估训练好的模型的效果?
A2: 评估模型效果的方法有很多,具体取决于任务的性质和目标,对于分类任务,常用的评估指标包括准确率、精确率、召回率和F1分数等;对于回归任务,则常使用均方误差(MSE)和决定系数(R²)等指标,还可以使用交叉验证等方法来评估模型的稳定性和泛化能力,选择合适的评估指标和方法可以帮助我们更准确地了解模型的性能和改进方向。