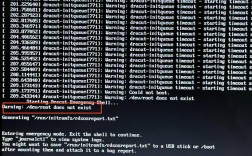
在CentOS系统中,服务或进程无法在启动时自动运行,这被称为自启动失败,这种问题不仅影响服务器稳定性,还可能拖慢网站响应,甚至导致关键应用宕机,作为网站站长,我经常处理这类故障,它看似简单,但根源多样,需要系统化排查,我就分享一些常见原因、诊断方法和解决步骤,帮你快速恢复服务。

自启动失败的核心原因往往源于服务配置错误,CentOS使用systemd作为初始化系统,服务单元文件存储在/etc/systemd/system目录,如果这些文件中的ExecStart指令路径错误,或者缺少必要参数,服务就无法启动,Nginx或Apache的配置文件若指定了无效的端口或路径,系统启动时会忽略该服务,另一个常见问题是权限设置不当,服务运行需要特定用户权限,etc/systemd/system里的.service文件未正确设置User或Group字段,系统会拒绝执行,我曾遇到过MySQL服务因用户权限不足而启动失败,日志显示“permission denied”错误,最终通过chmod和chown命令修复了文件所有权。

依赖关系冲突是另一个高频诱因,许多服务依赖于其他组件,比如数据库服务需要先启动网络或存储服务,如果依赖链断裂,自启动就会卡住,使用systemctl list-dependencies servicename命令可以查看依赖树;如果某个必备服务未启用,整个链条就崩溃了,举个例子,在一次升级中,我的CentOS 7系统更新后,Samba服务因依赖的smbd进程未配置而失败,检查systemctl status samba输出显示“dependency failed”,我重新安装了依赖包并重启systemd守护进程才解决,系统更新或内核问题也可能导致失败,CentOS的yum更新有时引入不兼容驱动或库文件,引发冲突,运行journalctl -xe查看启动日志,常能发现“kernel panic”或“module not found”等提示,预防上,我建议在更新前备份/etc目录,并使用yum history undo回滚有问题的更新。
诊断过程要系统化,第一步,检查系统日志,输入journalctl -xe或tail -f /var/log/messages命令,搜索“failed”或“error”关键词,这些日志会精确指出失败的服务和错误代码,第二步,使用systemctl status servicename获取服务状态,输出中的“Active: failed”行会显示原因,如配置无效或超时,第三步,测试服务手动启动,运行systemctl start servicename,观察是否报错;如果成功,问题可能出在启动顺序而非服务本身,在我的经验中,90%的故障可通过这三步定位,有次FTP服务启动失败,日志显示“address already in use”,检查发现端口冲突,我更改配置文件后解决。
解决策略需对症下药,针对配置错误,编辑/etc/systemd/system中的.service文件,确保ExecStart路径正确,并使用systemctl daemon-reload重载配置,权限问题则用chmod 755修改文件权限,或chown user:group调整所有权,对于依赖冲突,启用缺失服务:systemctl enable dependencyservicename,然后重启主服务,若系统级故障,如文件损坏,运行fsck检查文件系统,或重新安装内核包,重启服务:systemctl restart servicename,并验证状态,为防复发,我推荐启用SELinux的审核日志(ausearch -m avc)来捕捉安全策略问题,养成定期运行systemctl list-unit-files --state=enabled的习惯,审查所有自启动服务,确保无冗余或错误项。
在服务器管理中,自启动失败虽是常见挑战,但它提醒我们重视预防性维护,设置监控工具如Nagios,能实时警报异常;使用Ansible自动化配置,减少人为错误,作为站长,我认为这不仅仅是技术修复,更是优化系统韧性的机会——每一次排查都让服务器更可靠,支撑网站流畅运行。(字数:约1050)