CentOS SSH连接慢:UseDNS no立即生效
远程连服务器,手指都悬麻了,黑窗口才慢悠悠弹出密码提示?别急着砸键盘,八成是SSH在后台搞DNS反向解析,拖了整段节奏。把UseDNS no拍进去,重启服务,三十秒不到,登录滑得像热刀切黄油。

先别改配置,确认是不是DNS在捣鬼
开两个终端,一边开着ssh -v 用户@IP,一边tail -f /var/log/secure。日志卡在reverse mapping checking getaddrinfo for xxx不动,基本坐实了SSH在等人家的DNS回信。网络稍抖动,回包一丢,登录秒变“钝口”。
临时提速:当前会话直接加参数
只是偶尔连一次,懒得动配置文件?直接带参:ssh -o UseDNS=no 用户@IP,跳过反向解析,秒进。缺点也明显:每次都得敲, teammate 记不住,脚本里也难维护。
永久生效:改sshd_config并温柔重启
1. 先备份:cp /etc/ssh/sshdconfig /etc/ssh/sshdconfig.bak

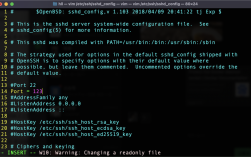
编辑:vi /etc/ssh/sshd_config,找到#UseDNS yes,改成UseDNS no,去掉注释符,保存。
检测语法:sshd -t,没报错再下一步。
重启服务:systemctl restart sshd,当前连接不会断,新会话立刻起飞。
老系统没systemctl?service一样好使
CentOS 6 及更老版本:service sshd restart,效果相同。记得把UseDNS写对,大小写敏感,多敲一个空格都能让配置失效。
多了一层保险:GSSAPI也顺手关掉

有些内网环境还开着Kerberos,GSSAPIAuthentication默认yes,同样会拖慢握手。顺手改成GSSAPIAuthentication no,重启sshd,双杀延迟。
云主机特别提示:安全组与DNS无关
控制台里安全组、ACL、iptables规则只负责放行22端口,不会帮你做解析。别把延迟甩锅给云平台,改完UseDNS依旧卡,再查内网DNS指向是不是公网不可达。
批量机器?Ansible一条命令全推下去
写个最简playbook:
• hosts: all
tasks:
• lineinfile: path=/etc/ssh/sshd_config regexp='^#?UseDNS' line='UseDNS no' backup=yes
• service: name=sshd state=restarted
执行:ansible-playbook -i inventory fix_ssh.yml,百台机器同步提速,运维早下班。
改完还是慢?再查三条暗坑
1. 客户端DNS:本机/etc/resolv.conf填了超时地址,ssh会先查客户端解析,再连服务器。
banner延迟:/etc/ssh/sshd_config里Banner指向网络盘,文件读取超时。
netfilter追踪:conntrack表爆满,SYN包被重播,握手看似正常实则重试多次。dmesg | grep conntrack一看便知。
日志里找不到UseDNS?版本差异别慌
CentOS 8 Stream之后部分精简版镜像默认注释掉该行,找不到就手动加一行UseDNS no,放哪都行,sshd读取顺序无关,只要别写进Match块里。
容器场景也适用
跑Docker的CentOS镜像,22端口映射到宿主机,容器内sshd配置一样改。重启容器后配置会丢?把新配置写进镜像Dockerfile:
RUN echo 'UseDNS no' >> /etc/ssh/sshd_config
构建、推送、重新拉起,延迟问题不再复现。
SSH卡顿九成是DNS反向解析,CentOS系列通用解法:改配置、重启服务、顺手关GSSAPI。单台手动三十秒,批量Ansible一条命令。改完仍卡,再查客户端DNS、banner、conntrack。思路理清,排障像呼吸一样自然。